Oncrawl, société française créée en 2013 par Francois Goube et Tanguy Moal, a développé un outil SEO qui peut être utilisé à la fois comme Crawler SEO et/ou comme Analyseur de logs serveurs, le tout en ayant la possibilité de plugger toutes sortes d’outils externes comme la Google Search Console, Google Analytics, AT Internet, Majestic SEO, SEMrush, etc …
Vous l’aurez compris, cet outil est puissant et il facilite aujourd’hui l’analyse SEO d’un site web. Avec OnCrawl, nous pouvons ainsi croiser toutes les données SEO que nous récoltons via différentes plateformes. Cela va nous permettre de comprendre comment Google explore et analyse les pages de notre site et quels sont les critères les plus importants à ses yeux pour optimiser au mieux le référencement naturel d’un site.
Lors de la prise en main de l’outil, nous avons tout d’abord souhaité comprendre comment agissaient les robots de Google – dits Googlebots – au sein du site. Nous voulions nous assurer que les robots de Google crawlaient bien toutes les pages de notre site ou du moins, les pages les plus importantes telles que la page d’accueil, les pages “catégorie” ou encore les articles de notre blogue. Pour cela, nous avons donc récupéré les logs serveurs du site sur les trois derniers mois puis nous les avons pluggé à l’outil Oncrawl.
L’analyse des logs et du budget de crawl
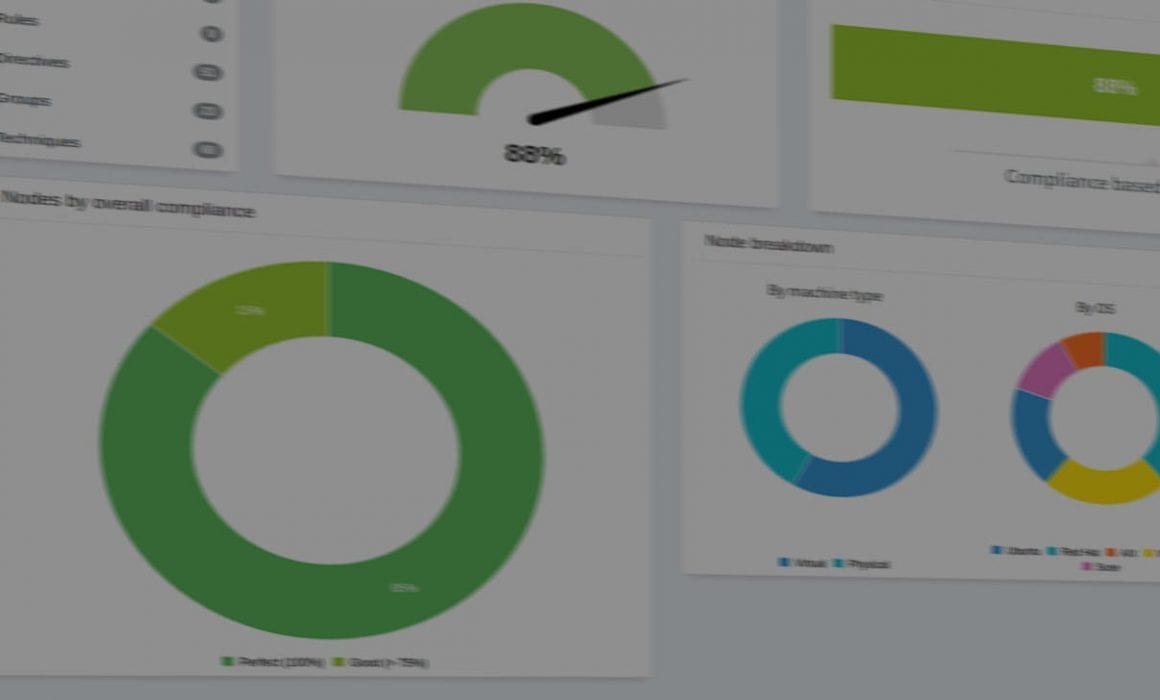
La première découverte, que nous avons faite en regardant les résultats de l’analyse de logs, c’est l’arrivée du Google Mobile First-Index sur notre site. D’après Google, notre site serait prêt à passer au Mobile First-Index puisque le passage des Googlebots Mobile (48.6%) et aujourd’hui quasiment égal au nombre de Googlebots Desktop (51.4%).
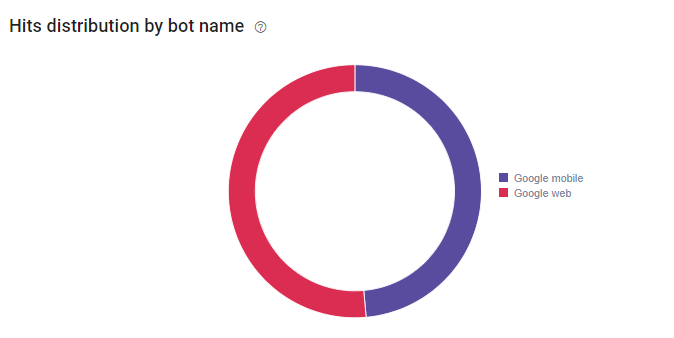
La seconde grande découverte, dont l’outil nous a fait part, concerne le passage des robots au sein des pages du site. Sur une période de 30 jours (27 février au 28 mars 2018), les robots de Google sont passés 13092 fois sur différentes pages du site, 460 pages uniques.

Si nous rentrons dans le détail des pages uniques qui ont été crawlées par Google, nous nous apercevons que sur l’ensemble des logs serveurs et des 13092 hits (mobile et desktop), 89% proviennent de deux pages seulement. Cela signifie que 9 googlebots sur 10 crawlent les pages https://dialekta.com/fr/blog?lang=fr et https://dialekta.com/blogue/?lang=fr.
Ces deux pages sont crawlées 188 fois par jour alors que de son côté, la page d’accueil, qui est censée être la page la plus importante et la mieux maillée dans l’arborescence du site, est « hitée » seulement 14 fois par jour (424 hits sur la période donnée).
Grâce à l’analyseur de logs, nous savons donc qu’à date, les pages les plus importantes pour Google sont des pages d’accueil du blogue, des pages qui ne sont actuellement pas les bonnes pages du blogue. En effet, la page d’accueil du blogue Dialekta est la suivante : https://dialekta.com/fr/blog
Cet élément nous permet d’affirmer que Google n’analyse pas le site comme nous le souhaitons car 89% du budget de crawl est alloué à des pages qui n’ont pas d’intérêt pour le site. Il ne reste donc que 11% du budget de crawl alloué pour les autres pages du site, ce qui n’est pas suffisant et cela se voit ci-dessous.
En effet, la fréquence de crawl des pages actives du site – pages qui génèrent au moins une visite – est inférieur à 1.

Cela se confirme sur le graphique ci-dessous, ou nous apercevons que parmi les pages actives SEO, seule la page d’accueil (répertoire Home) est crawlée fréquemment (+ de 5 hits par jour).
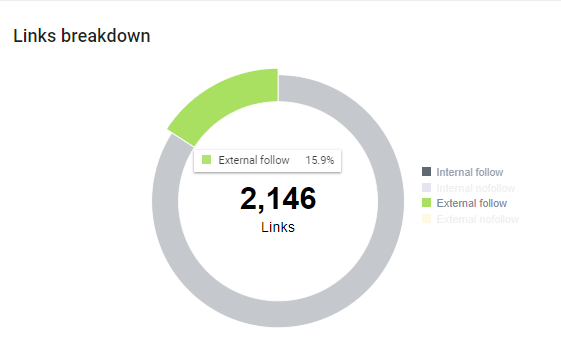
De plus, grâce au crawler, nous avons détecté une grande présence de liens externes follow qui, en soi, font perdre du Google Juice – ou Link Juice – aux pages du site Dialekta, puisqu’elles transmettent leur popularité à des pages externes.
Le plan d’actions
Suite à ces résultats, nous avons mis en place deux actions ayant pour but de redistribuer le budget de crawl au sein des pages actives du site afin qu’elles puissent être explorées par les robots de Google et revalorisées pour un meilleur positionnement dans les moteurs de recherche.
- La première de ces deux actions a été de mettre en place une redirection 301 sur les deux pages https://dialekta.com/fr/blog?lang=fr et https://dialekta.com/blogue/?lang=fr vers la bonne page d’accueil du blogue – https://dialekta.com/fr/blog/. En testant cette action de redirection, nous espérons que le budget de crawl soit redistribué via la page https://dialekta.com/fr/blog/ vers les pages articles du blogue.
-
La seconde action a été d’ajouter la balise rel= »nofollow » aux liens externes follow qui distribuaient du Link Juice aux pages externes. En ajoutant cette balise, nous souhaitons garder le link juice sur les pages du site et valoriser la notoriété de nos pages par Google afin d’améliorer leur positionnement dans les moteurs de recherche.
Une fois ces deux actions implémentées, nous avons laissé quelques semaines se passer afin que Google puisse correctement prendre en compte ces changements.
L’analyse des résultats suite aux actions
Un mois après les changements effectués sur le site de Dialekta, nous avons de nouveau récupéré les logs serveurs sur une période de 30 jours (9 mai au 7 juin 2018) comme nous l’avions fait précédemment. Et les résultats ont été assez probants.
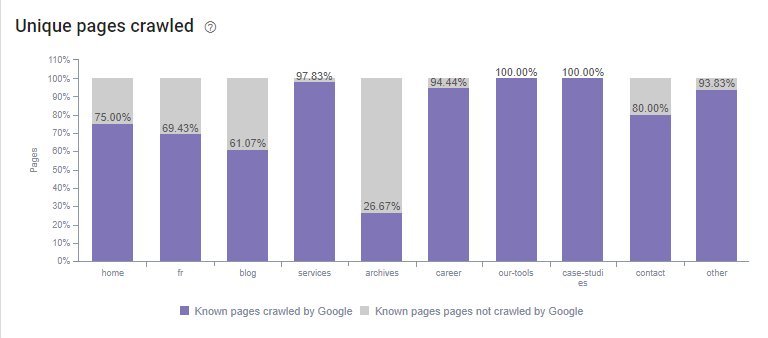
Tout d’abord, le nombre de pages uniques crawlées a augmenté de 36%, passant de 460 à 627 pages uniques crawlées. Cela signifie que le budget de crawl est mieux distribué sur l’ensemble des pages du site.
Période – 27 Février au 28 Mars 2018

Période – 9 Mai au 7 Juin 2018
Cela se confirme lorsque l’on regarde le crawl ratio du site et qu’on le compare avec le précédent crawl ratio. Avant, le crawl ratio était de 73.5% ce qui signifie que 26.5% des pages du site Dialekta – connu par Google et Oncrawl – n’étaient pas crawlées par les Googlebots. De plus, 43% des pages présentes dans la structure du site n’étaient pas non plus crawlées.
Suite au plan d’actions, nous avons aujourd’hui 96% du crawl ratio utilisé et aujourd’hui, seulement 0.35% des pages maillées ne sont pas explorées par les robots de Google.
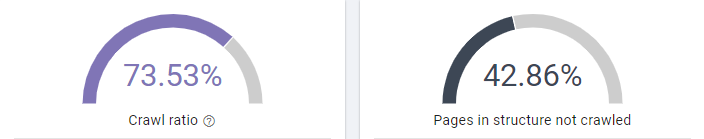
Période – 27 Février au 28 Mars 2018
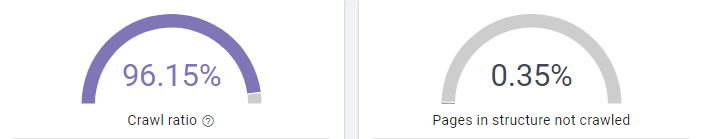
Période – 9 Mai au 7 Juin 2018
En plus de cela, nous notons l’augmentation de la fréquence de crawl sur les pages actives du site Dialekta. Si la fréquence de crawl globale a légèrement diminué, la fréquence de crawl des pages actives a quant à elle été multipliée par 5,5.

Période – 27 Février au 28 Mars 2018

Période – 9 Mai au 7 Juin 2018
Nous constatons donc une évolution du budget de crawl qui se met à crawler de plus en plus de pages maillées au sein du site. En effet, la grande majorité des pages du site est maintenant crawlée.
Période – 27 Février au 28 Mars 2018
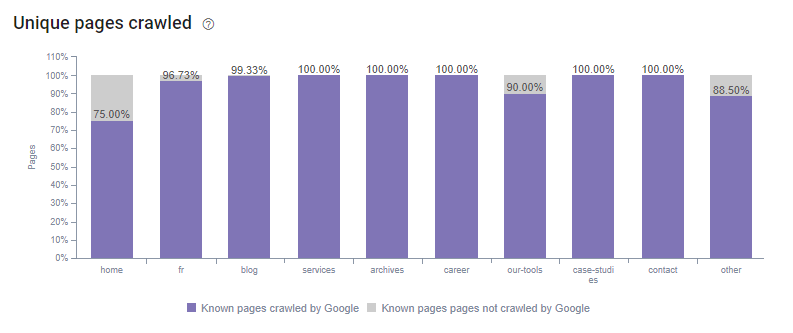
Période – 9 Mai au 7 Juin 2018
Conclusion
Grâce à l’analyse de logs fournie par Oncrawl, nous avons réussi à redistribuer le budget de crawl sur presque toutes les pages et répertoires du site en implémentant seulement deux actions. Suite à ces changements, nous pouvons aujourd’hui constater que toutes nos pages de niveau 1 à 6 sont toutes crawlées et que 96.5% de nos pages de niveau 7 sont également crawlées. Ce qui n’était pas le cas auparavant …
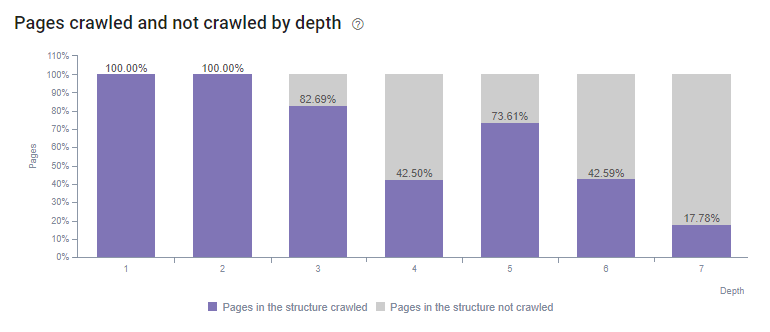
Période – 27 Février au 28 Mars 2018
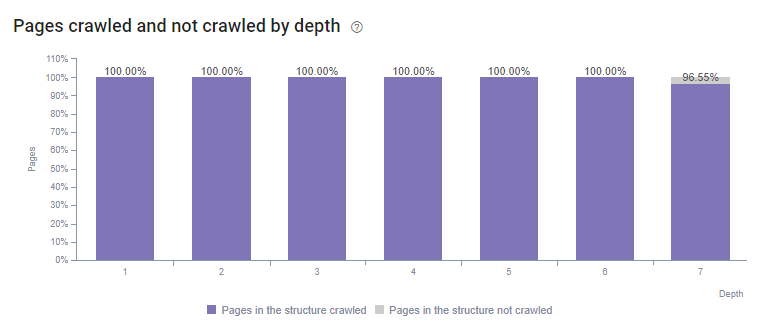
Période – 9 Mai au 7 Juin 2018
L’analyse de logs est aujourd’hui un élément incontournable dans l’analyse SEO d’un site web. En effet, si vous souhaitez optimiser les pages d’un site avant même de comprendre comment Google l’interprète, alors, il se peut que vous optimisiez des pages qui ne sont, à la base, même pas crawlées par les robots de Google. Si cela est le cas, alors vos optimisations SEO n’auront pas de gros impacts sur vos pages.
Il faut savoir que dans notre situation, sans l’analyse de logs, nous n’aurions jamais pu savoir que Google ne considérait qu’une toute petite partie des pages de notre site. Alors si vous aussi, vous souhaitez mieux comprendre comment Google explore votre site via l’analyse de logs, contactez-nous afin que nous puissions vous rencontrer et vous en parler.